Given all the information out there this week about Intent-Based Networking Systems (IBNS), I always think it is good to separate the “martketecture” from the reality. We are embarking on a new era that could rival that of the days of SDN as the “future of networking.” We will see more “PowerPoint engineering” in the coming weeks with the associated tweets and blog posts that will make even the most skeptical network engineers question their protocol knowledge and existence.
Let’s start with what is “Intent-Based Networking?” I actually love famed Gartner Analyst, Andrew Lerner’s definition of what is an Intent-Based Networking System:
- Translation and Validation– The system takes a higher-level business policy (what) as input from end users and converts it to the necessary network configuration (how). The system then generates and validates the resulting design and configuration for correctness.
- Automated Implementation– The system can configure the appropriate network changes (how) across existing network infrastructure. This is typically done via network automation and/or network orchestration.
- Awareness of Network State– The system ingests real-time network status for systems under its administrative control, and is protocol- and transport-agnostic.
- Assurance and Dynamic Optimization/Remediation– The system continuously validates (in real time) that the original business intent of the system is being met, and can take corrective actions (such as blocking traffic, modifying network capacity or notifying) when desired intent is not met.
Even in a recent article Lerner goes on to describe a vendor’s recent IBNS launch:
“It’s a platform that should enable intent driven network management in the future,” he says. “Except for some discrete, tight use cases around configuration, it’s not quite completely glued all together yet.”
So there you have it, vendors already claiming that they have an IBNS solution – which is really a bunch of disjointed parts – sound familiar? Aren’t we really jumping the gun? The same thing happened with Software Defined Networking – everyone claimed to have an SDN solution. In fact a common question I would get is “what is your SDN solution?” Ugh, let’s play buzzword bingo and see who is left standing.
As a kid one of my favorite shows was Looney Tunes where Wile E. Coyote would chase the Road Runner endlessly utilizing every method that he could to catch that bird.

In the picture above, this was the standard approach – he would lite the fuse on the rocket to go fast only to blow up when that approach reached its conclusion. You see Wile E. had a great intent – to catch the Road Runner. However he was operating from a flawed platform and approaches. You know how the story goes – again and again he tries and fails, at times blowing himself up, other times he would fall off a cliff. The moral of this story today is that his intent was great and maybe even the method seemed like a good idea, but he lacked the basic understanding of how things worked in his endeavor.
Another popular perspective is Maslow’s Hierarchy of Needs that was updated around 1954. Maslow’s theory suggests that the most basic level of needs must be met before the individual will strongly desire the secondary or higher level needs
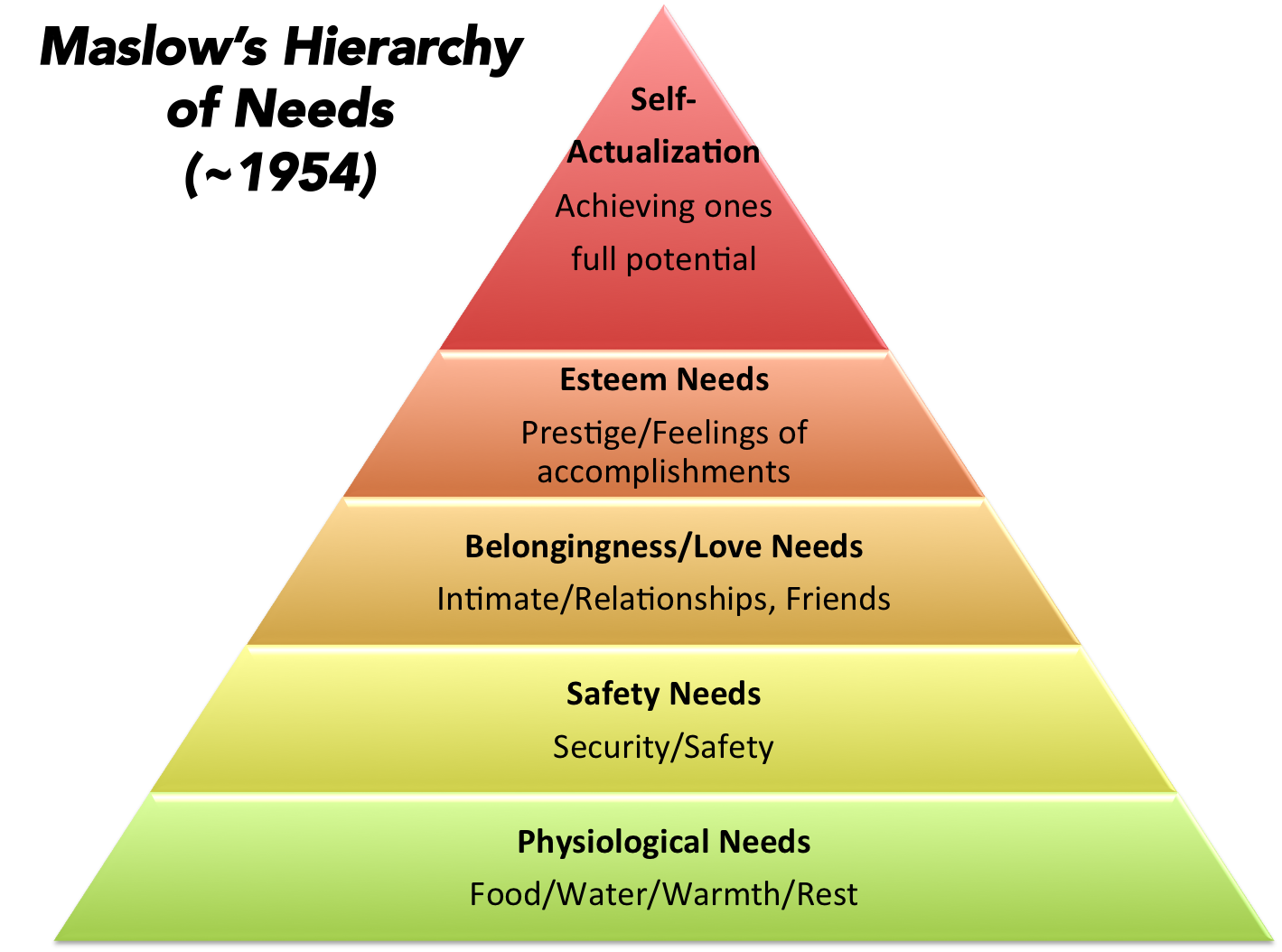
Being a bit of a psychology buff, this is fascinating to me because it very simply describes human behavior. I began to wonder if in fact that we could apply the “Hierarchy of Needs” to other parts of life.
So after much thought in the Intent-Based Networking space combined with my history of Service Management, Application Development, and 20 years in Networking, I decided to propose “DT’s Hierarchy of Networking Needs”
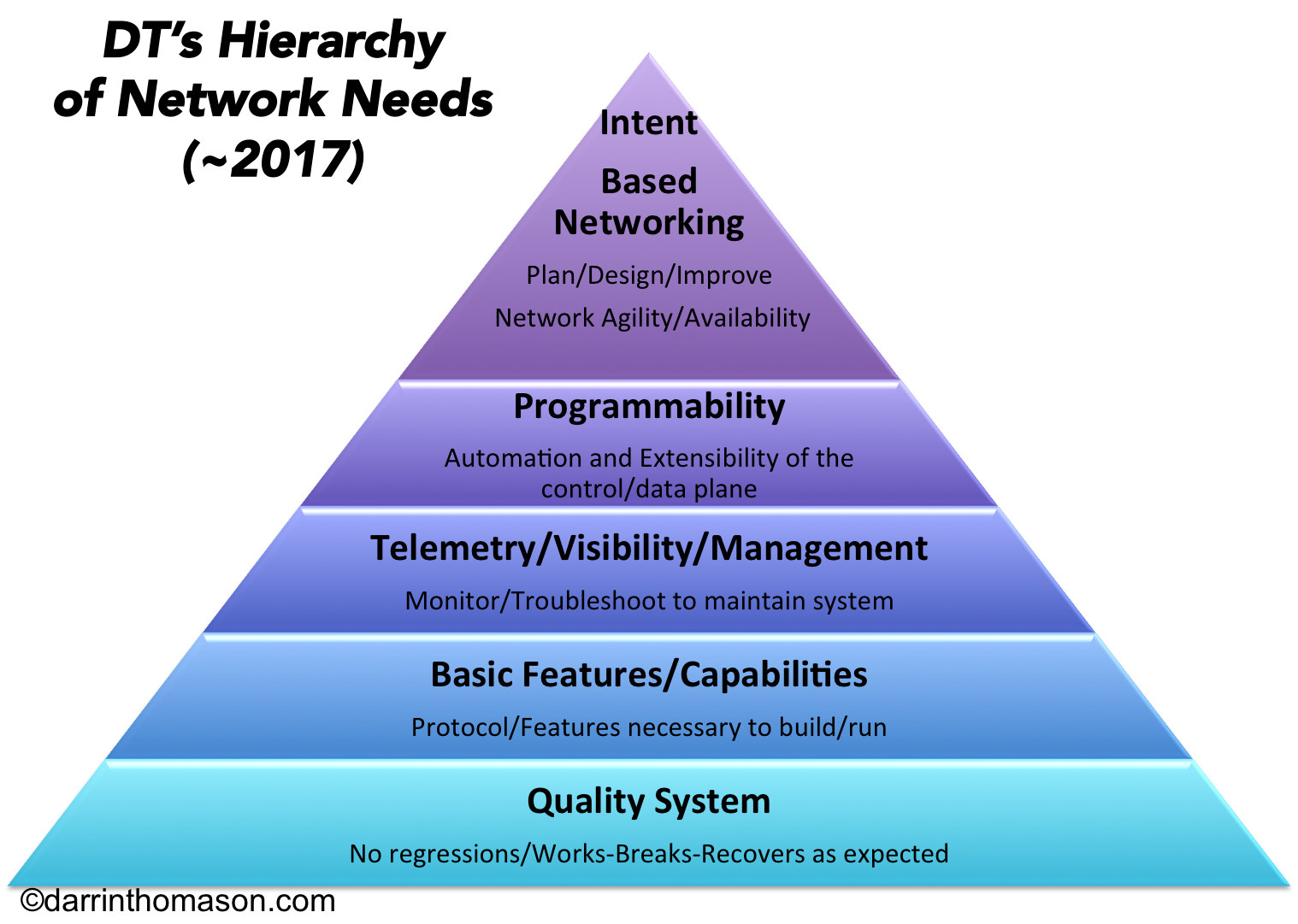
Let me explain each of these layers below:
Quality System
You have to start with Quality! Recently I had a customer comment to me that it was beautiful that when things broke, they broke and recovered the way we expected. You see things are going to break, bugs are going to happen, and even cosmic rays are going to cause SEUs. If a vendor tells you that things like this won’t happen they are lying to you. It all starts with having a good quality system that you ideally can update and patch without taking down the entire system. It begins with confidence that when you do an upgrade that you aren’t going to step into the quagmire of new bugs that lie in waiting for you to trip on them. As Ken Duda once said “If the network isn’t working then nobody is working!” So the basic principle that aligns to that of Maslow is you have to have the physiological needs met – in this case, high confidence that things work as expected with high quality.
Basic Features/Capabilities
Anyone can build a switch that can pass packets between two interfaces – if you can’t you don’t deserve to be in networking. After you can pass packets, you have to be able to do it under stress and scale. Then you start to organize things into a full system where devices talk to other devices. In order for this to work, you need to have some level of standards based protocol support such that everyone plays nice in the sandbox. Let’s face it, if you need STP support and one vendor doesn’t have it, you are up the proverbial “creek without a paddle.” Likewise if you are routing and you need BGP to handle the scale of routing – then that becomes a basic functionality. You must have a basic set of features and capabilities to make a system interoperate correctly.
Telemetry/Visibility/Management
Next after building a network where everything works together, you need to be able to manage the system for when things do happen. Those things could be misbehaving applications, cables going bad, NICs acting up, and even the occasional bug. Being able to see what is going on in the network is essential. We are moving in a new direction with things like streaming telemetry, which will be the death of SNMP (finally). This telemetry will also be a basis for us to engage in machine learning in the future as a critical data feed. You also need to be able to extract not just control plane information but you must be able to mirror ports and aggregate these mirrored ports for visibility for security, inspection, and troubleshooting. So the third need becomes the Telemetry/Visibility/Management of the network.
Programmability
The era of SDN ushered in new forms of programmability and automation that had been unheard of previously in the networking arena. You should be able to run your network with similar systems to managing your servers – in reality it is Linux under the cover so why wouldn’t you? We need to be able to inject our programmatic will into the control plane to steer packets in ways that are not in the natural order, we must be able to query the systems and leverage this information to provide proactive notifications of problems before they ever happen. Programmability goes way beyond that of a CLI – in fact I would say that the CLI will slowly age out in favor of programmatic/API integration into the network. The network is yours, so shouldn’t you be able to do with it what you want, versus a vendor telling you “only do it this way?”
Intent-Based Networking
We arrive at the top of the pyramid where we have reached the main goal in our networking lives – that of signaling the intent to the network and having it “auto-magically” instantiate this optimized network that has the security policy that you intend and it is automated in every way thinkable. Yes, I agree that it sounds like a utopia that we all would like to live in…
BUT – can you image trying to instantiate a network configuration when you have no confidence that the next bug you are going to trip over will loop your overlay and crush your users? Can you imagine trying to instantiate this network without well-formed APIs that cross vendor boundaries to make sure one vendor interoperates the same way with another? How about instantiating a network that is opaque in its monitoring and management capabilities? The reality here is that we have a lot of work as an industry to get the first 4 layers of needs satisfied. Yes I have an opinion as to what my current employer is doing and I do believe it is spectacular to get those pieces in order in a way that doesn’t lock a customer in. Customer’s should want to stay with a vendor, not because of some Vendor Defined Networking model but because they do have the highest quality in the industry, with the necessary features needed, combined with great telemetry and visibility, AND for the rainy day where I want to do something spectacular – I can program my way to the finish. This in my mind is where we as an industry must focus. It seems easy to create PowerPoint slides and videos of how this IBNS world will solve everything, but I ask you first to train and run the race – don’t just step over the finish line and declare victory!